About the data
The Crossref Event Data is centered around Events, but contains supporting data and metadata:
- Events record activity around registered content.
- Evidence Records provide an evidence trail for Events.
- Artifacts show some of the inputs that were used and feed into Evidence Records.
- Evidence Logs document the behavior of the system.
This section describes in detail exactly what data exists in Event Data, and what you should bear in mind when using it.
Why Events?
Each Event represents a single observation. It contains a subject-relation-object triple and also has other supporting fields and metadata that indicate how, why, where, and by whom the Event was created. In order to communicate all the relevant information, it's necessary to deliver data on this level of detail.
We track connections as they occur between objects, so you may wonder why the Event Data service is presented as a sequence of Events rather than a graph database of relations like, for example, Facebook's Graph API. There's two good reasons:
-
Firstly, we're observing a constantly changing web. We want to be able to provide all of this information to our users, and the best way to do this is a constant stream of Events that describe new links. If we stored the Events in a graph store it would be in a constant state of flux, with no way to let our users be confident that they have the entire data set at a given point in time. You are welcome to build your own database using the Event stream.
-
Secondly, there are many ways that Event Data could be modeled into a graph database. Choosing exactly how to do this involves interpreting the data, which is something we do not do. This subject is covered in depth in the Event Data as a Graph Data Structure page.
Because of this we present Event Data as a series of Events and you can decide if you want to create other representations in your own application. The Query API gives you the flexibility to scan over all data, or only to get those Events that were collected since your last visit.
The API also allows you to make queries like "all Events for this DOI" or "all Events for this tweet". The results for these queries will change over time.
Where we look
Data comes from different sources, via different routes. For some sources, like Crossref metadata and DataCite metadata, we receive Events directly from the source. For others, we operate an Agent to go and look for Events.
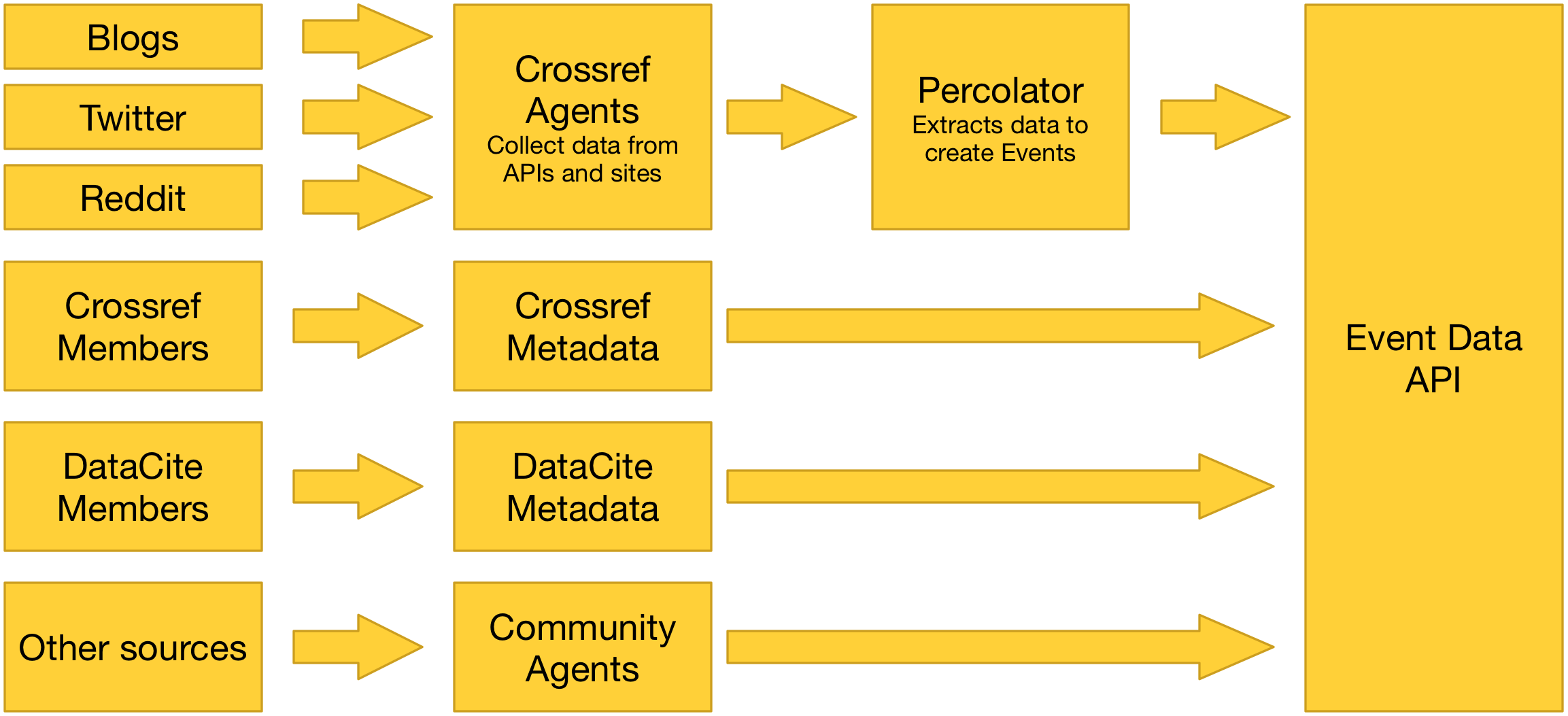
Events from each source go on a different journey to get into Event Data. Each Event provides documentation of its own provenance and links to supporting evidence, where applicable. Because of the diversity of routes by which data enters Event Data, you should consider which sources you are interested in. Each source is individually documented in this guide.
Because Event Data captures links between 'traditional literature' and 'non-traditional literature', the 'subject' of most Events is a webpage and the 'object' is a registered content item, linked via its DOI.
Crossref members already provide reference information for registered content, for example article-to-article citations. This falls under the 'traditional scholarship' category and is outside the scope of Event Data. If the publisher has made it open, this data is available via the Crossref REST API.
"Webpages" represent a wide variety of things, including members' sites. In order to avoid accidentally collecting 'traditional' reference information, all Crossref Event Data Agents avoid websites that belong to our members. We maintain a list of domains that the Event Data Agents will not visit because we know they belong to publishers. This exclusion is done on a best-effort basis.
We also exclude other webpages that we believe are part of databases, library systems etc. As we monitor a potentially limitless set of websites, this with is done with heuristics on a best-effort basis.
Sources and Agents
Event Data is a hub for the collection and distribution of a variety of Events and contains data from a selection of sources. Every Event is produced by an Agent operated by Crossref, DataCite or one of our partners. The Agent is responsible for connecting to an external data source and turning the data into Events. In some cases, the Agent is passing data directly through and in other cases the Agent has to do some work to extract the Event.
The Agents that Crossref operates attempt to co-operate, to prevent the same webpage being visited by two Agents so that they make exactly the same observation. However you may find that a (subject, relation, object) triple occurs in more than one source. For example, a blog post that's captured by the Wordpress.com Agent might also be included in an RSS feed monitored by the Newsfeed Agent, and might also be captured by the Web Agent. In this case there might be three Events that have the same blog URL subject and DOI object. You will need to interpret this kind of data, for example by de-duplicating duplicates, or by treating duplicates as extra corroboration.
For detailed discussion of each Agent, see its corresponding page.
| Name | Source Identifier | Operated by | What does it contain? |
|---|---|---|---|
| Crossref links | crossref | Crossref | Links to datasets and DOIs from registration agencies other tha Crossref (including DataCite) |
| DataCite links | datacite | DataCite | Dataset citations from DataCite items to Crossref Items |
| Hypothes.is | hypothesis | Crossref | |
| Newsfeed | newsfeed | Crossref | Links to items on blogs and websites with syndication feeds |
| Crossref | Mentions and discussions of items on Reddit | ||
| Reddit Links | reddit-links | Crossref | Mentions in pages shared on Reddit. |
| StackExchange | stackexchange | Crossref | |
| Wikipedia | wikipedia | Crossref | References of items on Wikipedia |
| Wordpress.com | wordpressdotcom | Crossref | References of items on Wordpress.com blogs |
The following agents have been deprecated and no longer provide events:
| Name | Source Identifier | Operated by | What does it contain? |
|---|---|---|---|
| The Lens | cambia-lens | The Lens, Cambia | Citations from Patents |
| Crossref | Links to items on Twitter | ||
| Web | web | Crossref | Links of items on web pages |
Every data source exists for a different reason, and therefore provides a different style of data. Every Agent operates slightly differently, according to its source. When you consume Events you should be mindful of the source they came from and the Agent that processed them.