Introduction
Before the growth of the Web, most discussion about scholarly content stayed within scholarly content, with articles referencing each other. With the growth of online platforms for discussion, publication and social media, we have seen discussions occur in new, non-traditional places.
The Event Data service captures this activity and acts as a hub for the storage and distribution of this data. The service provides a record of instances where research has been bookmarked, linked, liked, shared, referenced, commented on etc, beyond publisher platforms. For example, when datasets are linked to articles, articles are mentioned on social media or referenced in Wikipedia.
This data is of interest to a wide range of people: Publishers may want to know how their articles are being shared, authors might want to know when people are talking about their articles, researchers may want to conduct bibliometrics research. And that's just the obvious uses.
When a relationship is observed between a registered content item (that is, content that has been assigned a DOI by Crossref or DataCite) and a specific web activity, the data is expressed in the service as an 'Event'. The service provides Events from a variety of web sources. Each web source is referred to as a 'data contributor'. The Events, and all original data from the data contributor, are available via an API.
Event Data not only collects this data but also serves as an open platform for third parties to make their own activity data available to everyone. Anyone can build tools, services and research using this platform.
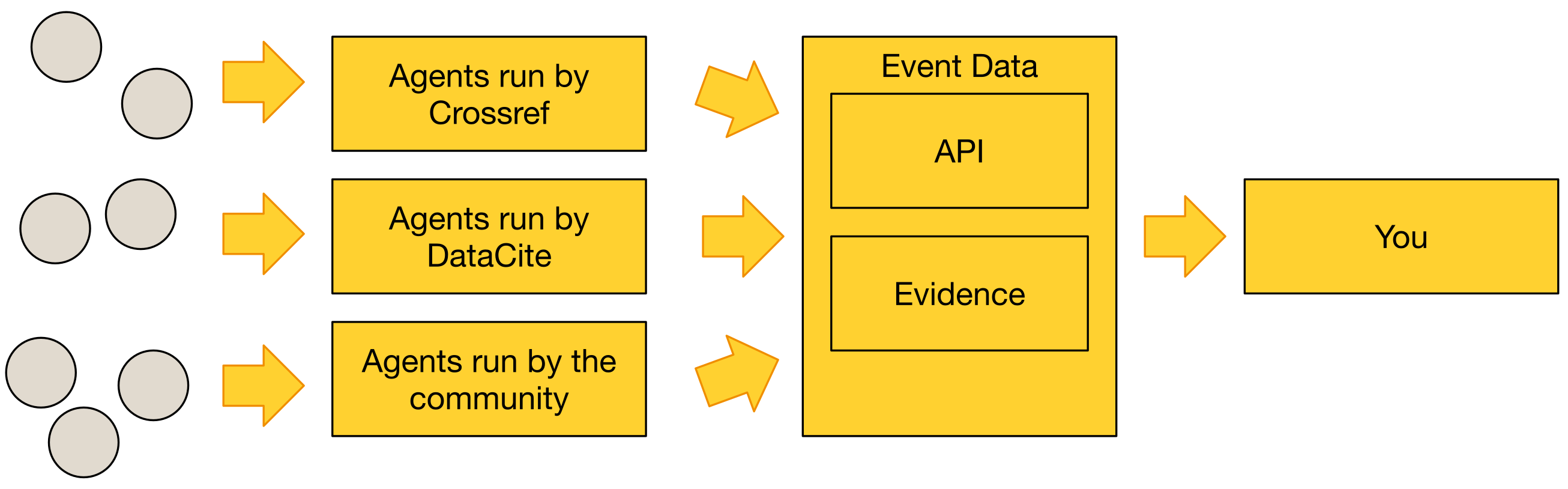
Events
Every time we notice that there is a new relationship between a piece of registered content and something out in the web, we record that as an individual Event. Examples include:
- An article was linked from a DataCite dataset via its Crossref DOI.
- An article was referenced in Wikipedia using its Crossref DOI.
- An article was mentioned on StackExchange using its Article Landing Page URL.
In this illustration every arrow connects two 'things':
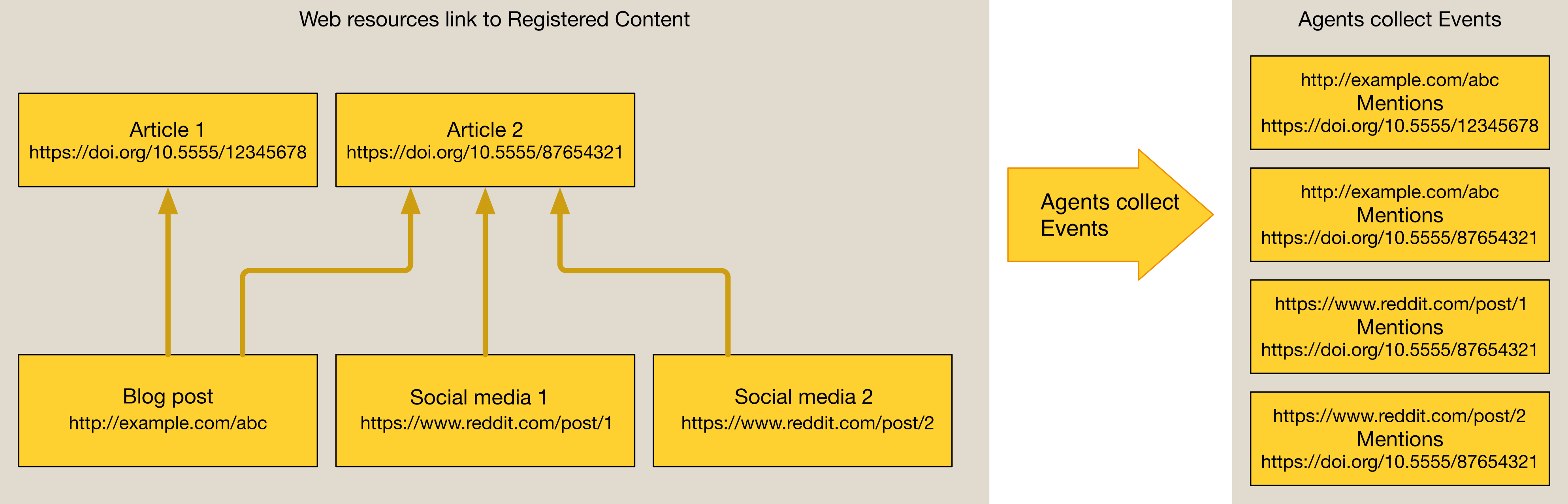
Subject - Relation - Object
An Event connects two 'things' with a particular relation type, like 'discusses'. Just like a 'subject verb object' sentence, every Event has a Subject, Relation type and Object field. The Subject and/or Object of an Event is usually a registered content item, referred to with its DOI.
For example:
| Field | Value | Reads |
|---|---|---|
| Subject | http://blog.example.com/1 | "The blog post with the URL http://blog.example.com/1 ..." |
| Relation type | discusses | " ... discusses ... " |
| Object | https://doi.org/10.5555/123456789 | " ... the article with the DOI http://doi.org/10.5555/123456789 ... " |
| Occurred at | 2017-01-01 | "... on the 1st of January 2017 ..." |
| Timestamp | 2017-02-02 | "... and we first knew about it on the 2nd of January 2017." |
Events vary from source to source, but they have a common set of fields:
- the subject of the event, e.g. Wikipedia article on Fish
- the type of the relation, e.g. "references"
- the object of the event, e.g. article with DOI 10.5555/12345678
- the date and time that the event occurred
- the date and time that the event was collected and processed
- a total for when an Event has a quantity
- the source of the data, known in the service as the Data Contributor
- optional bibliographic metadata about the subject (e.g. Wikipedia article title, author, publication date)
- optional bibliographic metadata about the object (e.g. article title, author, publication date)
Transparency and data quality
Data comes from sources all over the Web and each source is subject to different types of processing. Transparency of each piece of Event Data is crucial: where it came from, why it was selected, and how it was processed and by whom.
Every Event starts its journey somewhere, usually in an external source. Data from that external source is processed and analyzed, and, if we're lucky, one or more Events are created. The entire process is transparent: what data we were working from, what we extracted and how, and how that relates to each Event. Nearly all Events that Crossref generate are linked back to an Evidence Record, which documents its journey.

Crossref Event Data was developed alongside the NISO recommendations for Altmetrics Data Quality Code of Conduct, and we participated in the Data Quality Working Group. Event Data aims to be an example of openness and transparency. You can read the Event Data Code of Conduct self-reporting table in the Appendix.
Accessing the Data
Crossref Event Data is available via our Query API. The Query API allows you to make requests like:
- Give me all Events that were collected on 2016-12-08
- Give me all Events that occurred on 2015-12-08
- Give me all the Reddit Events that were collected on 2015-12-08
- Give me all the Events that occurred for this DOI on 2016-01-08
- Give me all the StackExchange Events that occurred for this DOI on 2016-01-08
The Query API allows you to collect Event Data in bulk, to make sure you're up to date.
Reliability and monitoring
The Evidence Logs describe the activity undertaken during the process of creating Events. This includes external API access.
Interpretation
Interpretation is a significant theme in Event Data, and it's something you must bear in mind when using the data. Every Event describes where it came from and who collected it. An Event can be interpreted several different ways. It's up to you to bear the origin and meaning of each Event in mind. This is discussed throughout the User Guide.